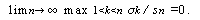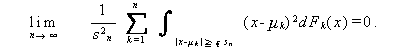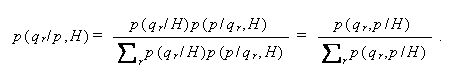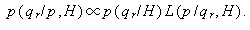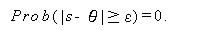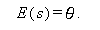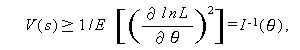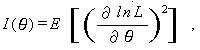![]()
このページは、平成11年6月7日に開設した。
このページは、令和2年4月24日に一部更新した。
統計学の基礎概念
A.1 事象・確率・標本空間
A.1.1 事象
統計学では、実験や観測結果のことを 事象 (event) と呼ぶ。例えば、 さいころを投げると、1から6の目のいずれかが出るが、それぞれは1つの事象 である。
事象 E に対して、E が起こらないという事象を E の
余事象 (complementary event) と呼ぶ。「2つの事象 E1 と
E2 が同時に起こる」という事象は
E1
![]() E2
と表される。
これに対して、「2つの事象 E1 と E2 のいずれかが起こる」という事象は、
E1
E2
と表される。
これに対して、「2つの事象 E1 と E2 のいずれかが起こる」という事象は、
E1
![]() E2
と表される。また、同時に2つの事象 E1 と
E2 が起こることが決してない時、E1 と E2 は
排反的 (exclusive) と呼ばれる。また、「事象 E1 が起これば
必ず事象 E2 も起こる」ということを、
E1
E2
と表される。また、同時に2つの事象 E1 と
E2 が起こることが決してない時、E1 と E2 は
排反的 (exclusive) と呼ばれる。また、「事象 E1 が起これば
必ず事象 E2 も起こる」ということを、
E1
![]() E2
と書く。この時、集合論では E1 は E2 の
部分集合 (subset) であるという。
E2
と書く。この時、集合論では E1 は E2 の
部分集合 (subset) であるという。
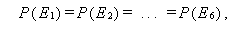
|
(A.1) |
である。
ここで、一般に起こりうるすべての異なる数の集合から成る事象を 標本 空間 (sample space) と呼ぶことがある。さいころの場合、それは 1,2,3, 4,5,6 である。これを Ω と表せば、一般に P(Ω)=1 である。
確率をより正確に定義すると、つぎのようになる:
一般に、標本空間 Ω は、さいころのような整数値を取る場合と、実数値 を取る場合がある。
このようにして定義される確率は、標本空間またはその部分集合に対して定義 できるので、一種の変数(変量)とみなすことができる。つまり、確率を標本空間 の部分集合の関数とみなす時、われわれはこれを 確率変数 (random variable) と呼ぶ。
一般に2つの事象 E1、E2に対して
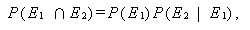
|
(A.2) |
が成り立つ。したがって、
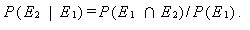
|
(A.3) |
上の式での P (E2 | E1) を、E1 のもとでの E2 の 条件付 確率 (conditional probability) という。(A.2) 式及び (A.3) 式とも、 E1 と E2 を交換すると、つぎの式が成り立つ:
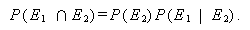
|
(A.4) |
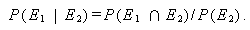
|
(A.5) |
もし、(A.2) 式で P (E2 | E1) が P (E2) に等しい時は、
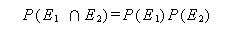
|
(A.6) |
が成り立つ。この時、2つの事象は 独立 (independent) という。
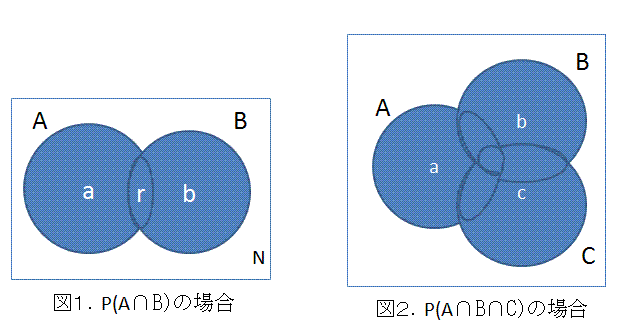
確率不等式(probability inequalities) 全般にわたる専門的な解説書の1つに Tong (1980) がある。例えば、多変量正規分布、多変量 t 分布、多変量カイ2乗分布、 多変量 F 分布、などは、それらのうちの1群である。この節では、各種確率不等式のうち、 分布によらない不等式(distribution-free inequalities) の中の基本的なものに ついてまとめる。これらは、分散分析における多重比較において、よく利用される。ただし、最初の「ブール の公式」は、不等式ではなく等式であることに注意せよ。
これについては、Hochberg & Tamhane (1987, p.363) が詳しい。それによれば、
E1, E2, ... , Ek,
k![]() 2
を確率事象(random events) とし、Eic
を事象 Eiの補集合(complement) とする時、
2
を確率事象(random events) とし、Eic
を事象 Eiの補集合(complement) とする時、
|
をブールの公式(又は、ポアンカレの公式)という。
 |
|
例えば Hochberg & Tamhane (1987) も指摘しているように、よく知られた ボンフェロニ不等式は、上記ブールの公式(AI.1) 式の 一次近似(the first order approximation) を用いるもので、
|
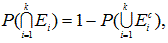 |
が成り立つので、
あるいは、
|
とも書ける。こちらの不等式の方が、分散分析の対比検定(とりわけ、計画的非直交対比に対する 対比検定)における実験当たりの過誤率αEW の上限値 (an upper bound) を与えるボンフェロニ不等式の 原型を与える式としては、直接的で理解しやすい。例えば、(AI.5)式で、Ai は、 i 番目の対比検定で帰無仮説が棄却されるという事象とみなし、個々の対比検定の危険率がすべて 一定でαである、と仮定すれば、この式は対比検定におけるよく知られたボンフェロニ不等式その ものであることは、明らか。なお、(AI.4)式の表現は、Hsu (1996, p.228)と同一。
あるいは、
|
|
あるいは、
|
(AI.8)式あるいは(AI.9)式の不等式の特徴は、
P(![]() Ai)
の上限値を構成する式の最後の係数が必ず正になる項
Ai)
の上限値を構成する式の最後の係数が必ず正になる項
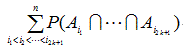 |
を含むという点であり、不等式は自明。
つまり、(AI.8)式または(AI.9)式は、ブールの公式の右辺の任意の偶数項(ただし、
-1 のべき乗のベキは奇数)までの和が
P(![]() Ai)
の下限値に、同じくその偶数項の次の項(ただし、-1 のベキは偶数)までの和が
P(
Ai)
の下限値に、同じくその偶数項の次の項(ただし、-1 のベキは偶数)までの和が
P(![]() Ai)
の上限値を示す式といえる。(AI.8)式は誰が提案した式かは、統計学辞典には書かれていない。
Ai)
の上限値を示す式といえる。(AI.8)式は誰が提案した式かは、統計学辞典には書かれていない。
(AI.3) 式のブールの公式の一次近似を同時2変量確率のみを用いてさらに改良したものが、 クニア(Kounias, 1968) により提案されている:
あるいは、
|
うえの式は、次のようにも書ける:
|
Tong (1980, p.147) の次の不等式は、クニアの不等式での
P(![]() Ei
c)の下限値についても加えたものである:
Ei
c)の下限値についても加えたものである:
|
Hochberg & Tamhane (1987)によれば、クニアの不等式はその後 Hunter (1976) 及び
Worsley (1982) が独立に同じ結果を得た。以下の結果は、グラフ理論
(the graph theory) に基づく。ここで、サイクル(cycle) を持た
ない連結グラフ (the connected graph)、すなわち
生成木 (the spanning tree) を T としよう。この時、もし T が頂点{1, ..., P}を
を持つ生成木であり、かつ
{i, j}![]() T は
i と j が隣接している (adjacent) ことを表すならば、次の不等式
が成り立つ:
T は
i と j が隣接している (adjacent) ことを表すならば、次の不等式
が成り立つ:
|
上式の最も精確な限界値は、右辺第2項が最大になるような生成木を見つけることにより得られる。 この問題を解くには、Kruscal (1956) の最小生成木アルゴリズム (the minimal spanning tree algorithm) を用いればよい(Hochberg & Tamhane, 1987, p.364)。
A.2.1 度数分布・母集団分布・標本分布
われわれが手にする (観測する) データは、それらが1変量であれ多変量であれ、 観測対象となる数値の集まり (これを、統計学では 母集団 (population) と 呼ぶ) の中から抽出される。ここで、対象となる母集団の数値の数が有限である 場合、 有限母集団 (finite population)、無限である場合、 無限 母集団 (infinite population) と呼ばれる。
また、抽出された N 個のデータは、サイズ (大きさ) N の 標本 (sample) と呼ばれる。
標本抽出の仕方についての2つの重要な概念に、復元・非復元、及び作為・無作為 がある。前者は、サイズ N の標本を選るに際して、一度抽出した個体を戻すか どうかで、戻さない抽出法を 非復元抽出 (sample without replacement)、 戻した後再度抽出する方法を 復元抽出 (sample with replacement) と それぞれ呼ぶ。
後者は、標本抽出を作為的に行うかどうかで、統計学の理論は 無作為抽出 (random sampling) による 無作為標本 (random sample) を前提にする。
さて、母集団での数値の集まりの特徴を見るためには、それらの値のそれぞれを 取る度数なり確率がどれだけあるかがわかればよい。それぞれの数値を横軸に取り、 対応する度数なり確率を縦軸にして、数値のばらつき具合を示したものは、 母集団分布 (population distribution) と呼ばれる。
有限母集団であれば、時間と費用をいとわなければ全数抽出すれば母集団分布は 正確に得られるが、多くの場合それは不可能で、母集団から適当なサイズの標本を 抽出し、それについての分布を描き母集団分布の特徴を推論する。
いずれにせよ、サイズ N の標本における数値を横軸に、度数を縦軸に取って、 数値のばらつき具合を示したものを、 度数分布 (frequency distribution) と呼び、通常母集団分布と区別する。
最後に、統計学ではこれらの他に、 標本分布 (sampling distribution) なる
概念も用いる。例えば、ある母集団からのサイズ N の標本を1つ得たとする。
また、その平均値を 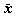 とする。
この は、異なる標本では
一般に異なる値を取る。つまり、 は標本を変えると、同一母集団から
からの標本であるにもかかわらずいろいろな値を取る、すなわちある分布を持つ
ことになる。通常標本平均は定数と考えるが、上の意味では定数ではなく確率変数
とも考えることができる。そこでそのような場合、われわれは
とする。
この は、異なる標本では
一般に異なる値を取る。つまり、 は標本を変えると、同一母集団から
からの標本であるにもかかわらずいろいろな値を取る、すなわちある分布を持つ
ことになる。通常標本平均は定数と考えるが、上の意味では定数ではなく確率変数
とも考えることができる。そこでそのような場合、われわれは 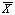 と書き、
と区別する。一般に、
のように標本から作られる量を
統計量 (statistic) と呼ぶ。また、その分布は標本分布と呼ばれ、上述の度数分
布や母集団分布と区別する。
と書き、
と区別する。一般に、
のように標本から作られる量を
統計量 (statistic) と呼ぶ。また、その分布は標本分布と呼ばれ、上述の度数分
布や母集団分布と区別する。
われわれが手にする度数分布は、前節から明らかなように多くの場合、何らかの 母集団分布からのサイズ N の無作為標本とみなされるが、母集団の 理論分布 (theoretical distribution) としては、これまでに多くの分布が提案されている。 これらの分布は、いろいろな角度からの分類が可能であるが、1つの方法は分布を 離散的分布 (discrete distribution) と 連続分布 (continuous distribution) とに分類することである。離散的分布とは、標本空間の要素がさいころ の目の場合のように飛び飛びの値を取る場合であり、連続分布とは、それらが連続 的な値を取る場合である。離散的分布としては、 2項分布 (binomial distribution)、 多項分布 (multinomial distribution)、 ポアソン分布 (Poisson distribution) などが、また連続分布としては、 正規分布 (normal distribution)、 F-分布 (F-distribution)、 t-分布 (t-distribution)、 χ2-分布 (chi-square distribution)、 などがよく知られている。
如何なる確率変数 X の分布も、分布が離散的であれ連続的であれ、標本空 間の各要素に対する確率が特定できれば決まる。そこで、これを
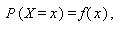
|
(A.7) |
と書くものとする。この式の f (x) を確率変数が離散型の時には単に 確率関数 (probability function) と、連続型の時には確率変数 X の 確率密度関数 (probability density function) と呼ぶ。確率密度関数は、 確率密度 (probability density) あるいは単に 密度 (density) と呼ばれることもある。
一般に、f(x) が確率関数、すなわち離散型の関数、の場合には、f(x) の値が1を超えることはないが、 f(x) が確率密度(関数)の場合には、分布によっては確率密度 f(x) は x のある範囲では 1を超えることがある。F-分布、カイ2乗分布、指数分布やベータ分布は、そのような例である。 しかし、A.1.2 節で述べた「確率」の定義での事象にあたるものは任意の連続分布の場合、特定の値 x で はなく特定の範囲(a 以上 b 以下)であり、x が特定の値を取る確率密度がたとえ1を超える値を持つ 分布の場合でも、x が特定の範囲に入る確率は1を超えることはないので、A.1.2 節の確率の定義に矛盾 しない。以下に、MATLAB による上記の分布のうち、F-分布及びベータ分布の確率密度関数の例を示す。
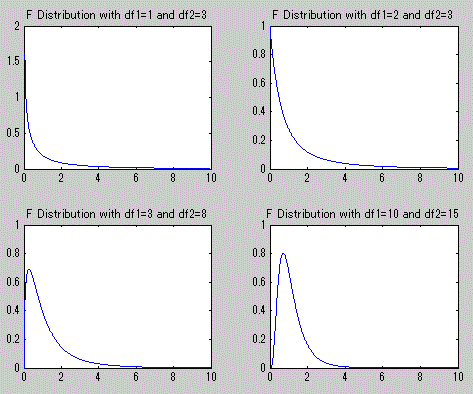
図3. F-分布の確率密度関数の例
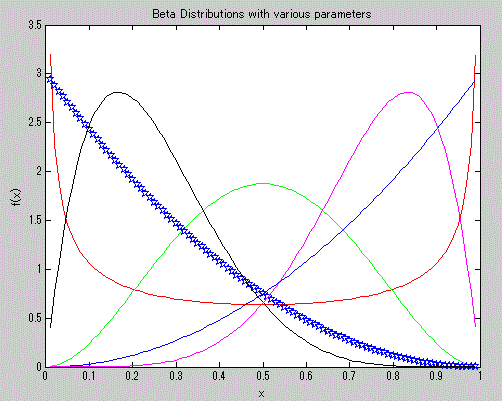
図4. ベータ分布の確率密度関数の例
一方、X が離散型か連続型かにより、
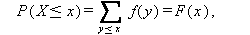
|
(A.8) |
または、
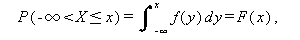
|
(A.9) |
なる関数を、 累積分布関数 (cumulative distribution function) もしくは 単に 分布関数 (distribution function) と呼ぶ。例えば、連続 分布の1つとしてよく知られた正規分布の確率密度(または密度関数)、及び 分布関数は、それぞれつぎのように書ける。ここで、正規分布の形を決める パラメータである平均値と分散は、それぞれ μ 及び σ2 であるとする:
まず、正規分布の確率密度関数は、
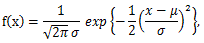
|
(A.10) |
である。ここで、正規分布はしばしば平均 μ と標準偏差 σ を用いて、 N(μ, σ) と 表記される。その幾つかの例を MATLAB で図示したのが、図5である。
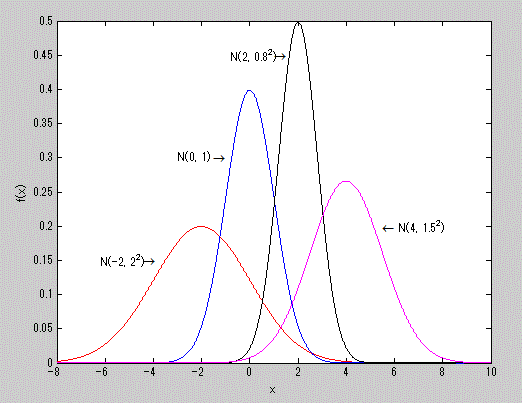
図5. 正規分布の確率密度関数の例
一方、正規分布の分布関数は、
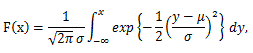
|
(A.11) |
である。また、正規分布 N(4, 1.5) の分布関数における x=3 までの累積 密度を青色で塗りつぶして示したのが図6である。
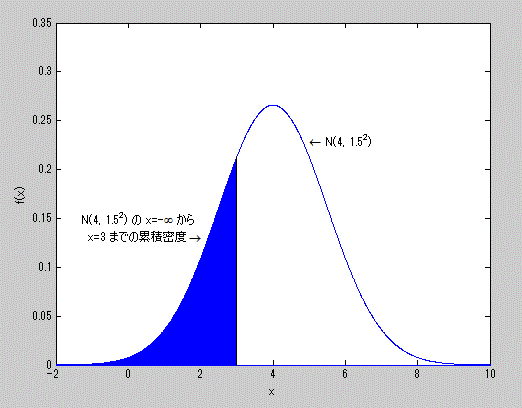
図6. 正規分布の分布関数による累積密度の例
確率変数 X の分布の特徴を表すための最も基本的な指標に、 期待値 (expectation) 及び 分散 (variance) がある。前者の期待値は平均値 とも呼ばれ、X が離散型か連続型かにより、それぞれ
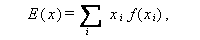
|
(A.12) |
または、
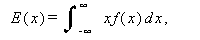
|
(A.13) |
として定義される。
期待値については、つぎのような性質がある:
|
後者の分散は、X が離散型か連続型かにより、つぎのように定義される。 ここで、E (X)=μ とする:
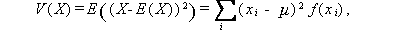
|
(A.17) |
または、
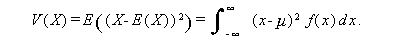
|
(A.18) |
一般に、X が離散型か連続型かにより、r\geq 0 なる正数に対して
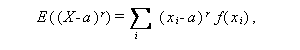
|
(A.19) |
または、
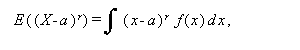
|
(A.20) |
を、確率変数の、任意点 a の周りの r 次の モーメント( 積率) (moment) と呼ぶ。上述の期待値は、その意味では原点 (a =0) の周りの1次 の積率であり、分散は、期待値(平均値)の周りの2次の積率と言える。また、 分散の平方根を 標準偏差 (standard deviation) と呼ぶ。
分散については、つぎのような基本的な性質がある:
|
最後の不等式は、 チェビシェフの不等式 (Chebyshev's inequality) と 呼ばれる。
ここでは、確率変数の和、平均値や分散などの基本的な統計量の分布について の定理を、裏西ら (1967) に従い証明ぬきで示す。また、基本的な 非心分布 (non-central distribution) についても列記する。最後に、 中心極限定理 (central limit theorem) にふれる。
|
|
|
|
|
|
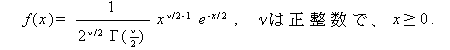
|
(A.25) |
|
図7は、MATLAB による自由度1から4までのカイ2乗分布の確率密度関数を示す。このうち、自由度1のカイ 2乗分布の x=0 における確率密度は無限大になるが、図では 1.2 をわずかに超えるところまでしか表示してい ないことに注意せよ。
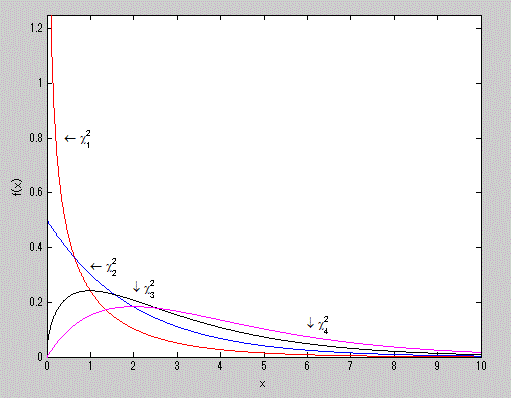
図7. カイ2乗分布の確率密度関数の例
|
図8. F-分布の確率密度関数の例
|
以下に、MATLAB による t-分布の例を2つ示す。まず、図9は自由度5の t-分布を赤色で示し、
さらにこの t-分布の分散が 5/3 になることに注意し、分散の等しい正規分布を青色で示したもの
である。
ここで、両分布とも、横軸 x の変域はもちろん定義よりマイナス無限大からプラス無限大に
亘るが、図9では、マイナス8からプラス8までしか描いていないが、両分布の尾の部分例えば
x の絶対値がおよぞ5より大きい部分の曲線は、縦軸すなわち f(x) の値が小さいためぼやけて
しまっている。
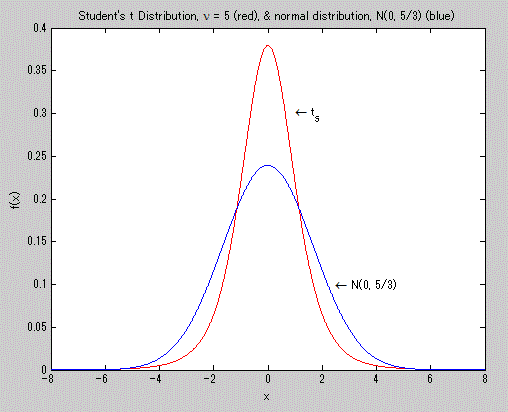
図9. t-分布の確率密度関数(赤色)の例(青色は正規分布の例)
つぎに、t-分布と正規分布が、両分布の分散が等しい場合、前者の方がより重くて大きな広がり
(heavier tails and a larger spread) を持つという特徴(例えば、Martinez et al., 2008, p.42)
を図示したのが、図10である。この図で両分布の尾の部分を比較すれば、その特徴は明らかで
ある。ここで、図10の縦軸のスケールは f(x)/1000、すなわち通常の1000分の1にしてある
ことに注意せよ。
なお、t-分布は極限では(自由度が無限大なる)正規分布と一致することもよく知られている。
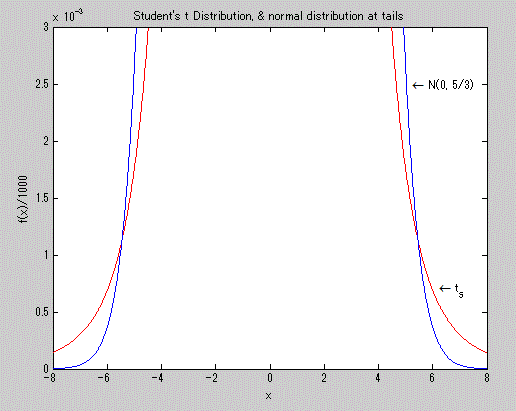
図10. t-分布の確率密度関数(赤色)(青色は正規分布の例)の尾の部分の特徴
|
まず、自由度 ν の 非心 χ2-分布 (non-central χ2
distribution) は、互いに独立な ν 個の正規分布 N(μi,1),i =1,
..., ν で 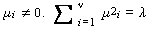 に従う
変数の2乗和の分布として定義される。ここで、λ をこの分布の
非心母数 (non-central parameter) と呼ぶ。
に従う
変数の2乗和の分布として定義される。ここで、λ をこの分布の
非心母数 (non-central parameter) と呼ぶ。
非心 χ2-分布で λ=0 の場合を、通常の(中心)χ2-分布 (central χ2 distribution または単に χ2 distribution) と呼ぶ ((A.25) 式)。
つぎに、互いに独立な2つの確率変数 U1 及び U2 が、それぞれ自由度 ν1 及び ν2 で非心母数 λ1 及び λ2 を持つ非心 χ2-分布に従うとする。この時、V =(U1 /ν1 )/(U2 /ν2 ) の分布は 二重非心 F -分布 (doubly non-central F-distribution) に従う。
二重非心 F -分布で、λ1 =λ かつ λ2 =0 と置いたもの は、一重の非心 F -分布となるが、通常これを自由度 ν1,ν2 で 非心母数 λ を持つ 非心 F -分布 (non-central F distribution) と呼ぶ。
非心 F -分布で、非心母数 λ=0 の時、通常の F -分布と呼ぶ ((A.27) 式)。
二重非心 F -分布で、ν1 =1 の場合を 二重非心 t2 -分布
(non-central t2-distribution) と呼ぶ。この分布で、t2 から t に
変換したものを 二重非心 t-分布 (doubly non-central t-distribution)
と呼ぶ。同様にして、(一重)非心 F -分布で、ν1 =1 の場合を非心
t2 -分布、さらに 、t2 から t に変換したものを 非心 t-分布
(non-central t -distribution) と呼ぶ。すなわち、互いに独立な2つの
確率変数 Z1 ,Z2 のうち、Z1 が N (λ ,1)、Z2 が自由度
nu の(中心)χ2 -分布に従う時、
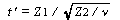 は、非心母数 λ を持つ、自由度 ν の t -分布に従う。
は、非心母数 λ を持つ、自由度 ν の t -分布に従う。
非心 t -分布は、非心母数 λ =0 の時、通常の t -分布 となる((A.28)式)。
これまで述べてきた各種の基本的な統計量の分布は、すべてそのもとになる 確率変数に対して、何らかの分布を仮定することにより導かれた。それに対して、 つぎに示す中心極限定理は、個々の確率変数に対してはその積率に対して非常に弱い 条件を課するだけで、確率変数の和の分布が標本のサイズを大きくすれば、正規 分布に近づくことを保証する。一口に中心極限定理といっても、最初の De Moivre-Laplace の定理から、Lyapunov の定理、Lindeberg-Feller の定理など があるが(例えば、柴田、1981)、ここでは Lindeberg-Feller の定理のみを示す。
|
この節では、Kendall and Stuart (1973) に従って、統計的仮説の検定と2 種類の過誤についてまとめる。
Kendall and Stuart (1973) によれば、一般に 科学的仮説 (scientific hypothesis) と呼ばれるものは、データに基づいてその真偽を検証するための 言明である。この特別な場合を、われわれは 統計的仮説 (statistical hypothesis) と呼ぶ。
統計的仮説検定におけるデータは、何らかの母集団からのサイズ N の標本 x1,x2, ... ,xN であり、 これを1つのベクトル x と考える時、 N 次元空間の点として表せる。したがって、この空間を標本空間と呼ぶ。この 標本空間の定義は、A.1.2 で述べたそれと若干異なるので、注意が必要である。
ベクトル x を確率変数とみなすと、それは一定の分布を持つ。したがって、 われわれがもし標本空間の中のある領域 w を選ぶとすれば、標本点 x が w に入る確率 P (x \in w ) を計算することができる。これに関する 仮説が統計的仮説である。
統計的仮説にはいろいろなものがある。1つは、分布の 母数 (parameter) に関するものであり、他方は分布の形に関するものである。前者は パラメト リック仮説 (parametric hypothesis)、後者は ノンパラメトリック仮説 (non-parametric hypothesis) と呼ばれる。
前節で述べたパラメトリック仮説にも、2種類を考えることができる。 ここで、ある分布の母数を θ1,θ2. ... ,θl と書くもの とする。この母数の組 (θ1,θ2. ... ,θl ) は、 母数空間 (parameter space) を構成する。
ある仮説が、この母数空間のうちの k 個を指定するものとする。もし、k = l ならば、その仮説は 単純仮説 (simple hypothesis) であると言い、もし、 k < l であれば、 複合仮説 (composite hypothesis) であると言う。
幾何学的には、もし仮説が母数空間内の点を指定するものならば単純仮説であり、 部分領域 (sub-region) を指定するものであれば複合仮説である。
観測値に基づいて、ある仮説を検定するためには、われわれは標本空間を 2つの領域に分けなければならない。もし、標本点 x がそれらのうちの 1つ例えば w に落ちるならば、われわれは仮説を 棄却 (reject) する。 これに対して、もし 標本点 x が補領域 W - w に落ちるならば、われわれ は仮説を 採択 (accept) する。また、ここで w を検定の 棄却域 (critical region of the test) と呼び、領域 W - w を 採択域 (acceptance region) と呼ぶ。また、検定される仮説を、 帰無仮説 (null hypothesis) と呼ぶ。
さて、帰無仮説のもとでの観測値の分布がわかれば、われわれは帰無仮説 H0 を棄却する確率があらかじめ設定された値 α に等しいような領域 w を 決めることができる。すなわち、
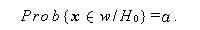
|
(A.30) |
この (A.30) 式の α を 有意水準 (level of significance) と呼ぶ。これを 検定のサイズ (size of the test) と呼ぶこともある。
帰無仮説と対立仮説の議論からは、統計的検定に際して2種類の過誤 (error) が 存在することがわかる。それらは、つぎの2つである。
第1種の過誤は、 危険率 (level of significance) に等しい。第2種 の過誤を β と書くとして、1-β を 検出力 (power of the test) と 呼ぶ。統計的検定における帰無仮説は、多くの場合、何らかの母数間に差がないことを 意味するので、検出力が高い(1-β の値が大きい)検定とは、母数間に差が ある時それを検出する力の大きい検定である、と言える。
一般に、帰無仮説の検定に際して同じ危険率を持つような棄却域のうち、いずれを 選ぶかという時には、第2種の過誤が最小、すなわち検出力が最大になるような 棄却域が望ましいと言える。このような棄却域は、 最良棄却域 (best critical region 略して BCR) と呼ばれる。また、BCR に基づく検定は 最強力検定 (most powerful test 略して MP 検定) と呼ばれる。
一般に、棄却域を分布の片側にとる検定を 片側検定 (one-sided test)、 分布の両側にとる検定を 両側検定 (two-sided test) と呼ぶ。例えば、 平均値の差の検定に際して、どちらの検定方式を用いるべきかは、対立仮説が どのようであるかによる。もし、対立仮説が単に両群に差があるというものであれば、 危険率を分布の両側に分けた方が、一般的に言って第2種の過誤を小さくするには 無難であることが容易にわかる。もっとも、検定によっては最初から片側検定しか 考えられない場合もあるので、注意が必要である。
A.5.1 Bayes の定理
|
Bayes の定理は、情報 H のもとで言明 p が真の時、N 個の排反的 言明のうち qr が真である確率は、qr が真である確率に、qr が真の 時に言明 p が真である確率を掛けたものに比例することを意味している。
前節の (A.31) 式は、つぎのようにも書ける。
|
ここで、(A.32) 式の右辺の L (p / qr,H ) は (A.31) 式の p (p / qr,H ) をそのように書き直したにすぎない。
さて、ここで p を広義のデータとみなしてみよう。この時、(A.32) 式の 左辺 p (qr / p,H ) は、情報 H のもとでデータ p が与えられた時、N 個の排反的仮説 q1 , ... ,qn のうちの qr が真である確率で、 事後確率 (posterior probability) と呼ばれる。
一方、(A.32) 式の右辺の p (qr / H ) は、データ p に無関係に、情報 H の もとで仮説 qr が真である確率と考えられ、 事前確率 (prior probability) と呼ばれる。
最後に、(A.32) 式の L (p / qr,H ) は、情報 H のもとで仮説 qr が真 の時、データ p を手にする確率であり、 尤度 (likelihood) と呼ばれる。
このように (A.32) 式を解釈すると、(A.31) 式の Bayes の定理は、つぎのように も言える:
|
例 壷の中に4つの球が入っているが、中は見えないとする。さらに、 球の構成は、(1) すべて白、か (2) 3つは白で1つは黒、のいずれであることは わかっているとする。この壷の中から球を1つ取り出しては元に戻す、すなわち 復元抽出を繰り返すとする。この試行から、球の構成についてのうえの2つの仮説 (これらをそれぞれ q1 , q2 であるとする)のいずれが真であるかを判断する 問題を考えてみよう。
まず、1つの球を取り出したら白であったとする。これがデータ p にあたる。 また、H は、このような条件下での第1試行時にわれわれが手にしている情報 を指す。この時、q1 , q2 の尤度は、
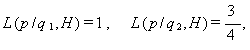
|
(A.33) |
である。
一方、この時の q1 , q2 の事前確率 p (q1 /H ), p (q2 /H ) は、共に 未知である。したがって、データ p すなわち第1試行で白い球を手にした時、 q1 , q2 が真である確率、すなわち事後確率は、計算できない。一般に、 このような事態に遭遇した時どうのような仮説を選ぶかについて、いろいろな 方法が提案されているが、それらのうちの代表的なものが、つぎに述べる Bayes の提案と最尤原理である。
事前確率が未知の場合の仮説選択の第1の方法は、 Bayes の提案 (Bayes' postulate)、または 不可知均等分布の原理 (principle of equidistribution of ignorance) と呼ばれ、統計的推論の理論の中で、最も大きな 論点の1つである。
|
第2の方法は、 最尤原理 (maximum likelihood principle) である。
|
一般に、サイズ N の標本 x1, ... ,xN から、それらが得られた母集団 の特徴を表す未知数、すなわち 母数 (parameter) θを特定する問題 を考えてみよう。この場合、帰無仮説 H0: θ=θ0r は、(A.32) 式 では、仮説 qr にあたる。
もし、θ の事前確率、すなわち p(θ =θ0r/H) が既知で あれば、Bayes の定理を用いてすべての仮説 r 個のそれぞれの事後確率を計算 し、データのもとで事後確率が最大になるような仮説 θ =θ0r/H を選べばよい。
しかし、一般には θ の事前確率は未知の場合が多い。このような時、 (A.32) 式の尤度 L(p / qr , H) 、すなわち仮説 H0: & theta;= &theta0r のもとでデータが得られる尤度を最大にする仮説を選ぶことにするのが、最尤原理 のこの問題への適用である。
さて、情報 H のもとでは、θ を母数とする密度関数が f(x /θ) であることがあらかじめわかっているとする。この時、標本 x1, ... ,xN の得られる尤度は、データがうえの分布に従う母集団からの互いに独立な標本 であるとすれば、
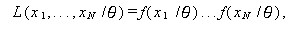
|
(A.34) |
と書ける。
(A.34) 式は、x1, ... ,xN の 同時分布 (joint distribution) を 与えるもので、正確には 標本の尤度関数 (likelihood function of the sample)、略して 標本の LF (LF of the sample) と呼ばれる。
最尤原理からは、θ の取りうる値の範囲(値域)で、LF を可能な限り
大きくするような 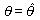 を選ぶのがよいことになる。そのような
は、 最尤推定量 (maximum likelihood estimator)
と呼ばれる。
を選ぶのがよいことになる。そのような
は、 最尤推定量 (maximum likelihood estimator)
と呼ばれる。
A.6.1 母数と推定量
(A.4.1) 節で既に母数の概念を、統計的分布に関して導入した。しかし、一般には 母数は分布のそれに限定されるものではない。われわれが何らかの統計的モデルを 考えるとき、それを特徴づける未知数(パラメータ)のことを、統計学ではすべて 母数 (parameter) と呼ぶ。したがって、母数には (A.4.1) 節における何らかの 分布のそれであることもあるし、何らかの統計的モデルの未知数であることもある。
いずれにせよ、統計学の基本的な課題は 観測値 (observation) としての 標本を手にしたとき、それを用いて標本が得られた母集団における未知の母数を 推定したり、母数についての何らかの帰無仮説が正しいかどうかを検討したり することである。後者は、検定の問題となる。
一般に、このような課題における標本から作られる量(関数)のことを統計量
と呼ぶことは、既に (A.2.1) 節で述べた。そこで述べた
をここでは
s と書くものとする。もちろん、
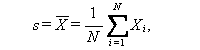
|
(A.35) |
であり、s は1つの統計量である。
さて、確率変数 X が平均 θ、で分散 σ2 に従うとすれば、 互いに独立なサイズ N の標本に対する確率変数の平均値 s は、
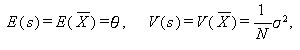
|
(A.36) |
なる正規分布に従うので、母平均 θ の 推定値 (estimate) として
の実現値
を用いることは、1つの合理的な方法と言える。
ここで、一般に s のような統計量が推定のために用いられる時、これを
推定量 (estimator) と呼ぶ。また、一般に何らかの母数をうえのような
1つの値で推定する方法を、点推定 (point estimation) と呼ぶ。
これに対して、母数をある区間に入る確率の言葉で推定する方法を 区間
推定 (interval estimation) と呼ぶ。
うえの s= については、
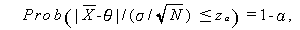
|
(A.37) |
が成り立つことを用いて、母平均 θ の信頼度 100(1-α) % の 信頼区間 (confidence interval) は、
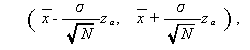
|
と書ける。ここで、zα は単位正規分布 N(0,1) の上側
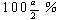 点を指す。
点を指す。
標本にもとづき母数 θ の推定を行う場合、θ の推定量が どのような性質を持つことが望ましいであろうか。これについては、従来から 数理統計学の分野では幾つかの特性が提案されてきた。1つは、推定量または その期待値と、その母数との一致・不一致に関する特性である。2つ目は、推定量 の 精度 (precision) とりわけ、推定量の ばらつき (dispersion) に 関するものである。3つ目は、推定量の持つ情報量に関するものである。4つ目は、 推定量の、母数からのばらつきに関するものである。
第1の性質には、 一致性 (consistency) と 不偏性 (unbiasedness) の2つがある。前者は、推定量の値が 漸近的に (asymptotically) (すなわち サンプル数が無限大になった時に)母数 θ に一致するかどうか、という 性質である。これに対して、後者は、有限のサンプル数の場合、すなわち 正確に (exact) 推定量の期待値が母数に一致するかどうかという性質 である。
第2の性質についても、 最小分散 (minimum variance、略して MV) 性に、 2種類がある。1つは、推定量の漸近的な最小分散性で、他方は有限サンプル の場合のそれ(この場合には、さらに、MV の場合と 最小分散限界 (minimum variance bound、略して MVB) の場合がある)である。漸近的な MV は、古典的、有限サンプルの場合は近代的な意味での 有効性 (efficiency) の定義である。
第3の性質は、推定量の持つ情報の多さに関するもので、 充足性 とか 十分性 (sufficiency) と呼ばれる。
第4の性質は、推定量の、母数からのばらつきの小ささであり、 最小平均 平方誤差 (minimum mean-square-error) である。
|
もう1つは、 強い意味での一致性 (consistency in the strong sense) で、
|
いずれの場合も、一致性を持つ推定量は、 一致推定量 (consistent estimator) と呼ばれる。
例えば、(A.2.4) 節のチェビシェフの不等式を推定量 に対して
適用すると、
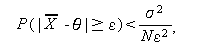
|
(A.40) |
が得られるので、N \to \infty$ の時 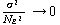 と
なり、したがって s = は母平均の一致推定量である。
と
なり、したがって s = は母平均の一致推定量である。
しかし、一般にある s が一致推定量であれば、例えば
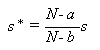
|
もまた一致推定量となる、すなわち一致推定量は一意的には定まらない。そこで、 有限のサンプル数に対して言及できる推定量の望ましい特性を考える必要性が 生じる。一般に、推定量 s の期待値が母数 θ に等しいとき、この推定量は 不偏性を持つといい、そのような推定量は、 不偏推定量 (unbiased estimator) と呼ばれる。正確には:
|
ならば、s は母数 θ の不偏推定量であるという。
推定量 s の精度は、しばしばその標本分散
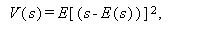
|
(A.42) |
で表される。推定量の多くは、中心極限定理により、漸近的には正規分布になる ので、n \to \infty$ の時、分布は平均と分散の2つの母数により決まる。 古典的には、漸近的に最小分散になるような推定量は、有効性があるといい、 そのような推定量を、 有効推定量 (efficient estimator) と呼ぶ。もっとも、 最近では漸近有効性も、1次、2次、3次等が区別されている。
いずれにせよ、古典的有効性が推定量の漸近的特性に関するものであるのに対して、 有限のサンプルの場合にも推定量 s の標本分散、すなわち精度に最小値が存在 することがわかったのは、比較的新しい。
Rao (1945) や Cram\'er (1946) により証明された クラメール・ラオの 不等式 (the Cram\'er-Rao inequality)
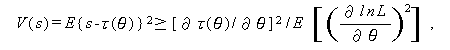
|
(A.43) |
は、推定量 s が母数 θ の関数 τ(θ) の不偏推定量である 場合に、推定量の最小分散限界 MVB を与える。
ここで、(A.43) 式の L は、互いに独立で同一な分布に従う (independent and identically distributed, 略して i.i.d. ) 母集団からの標本 x1, ... ,xN の尤度関数で、母数 θ のもとでの x1, ... ,xN の密度を f (x1 /θ), ... , f(xN / θ) と すれば、A.5.4 節の (A.34) 式として表せる。また、τ(θ) は、推定 量 s の期待値すなわち、
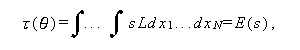
|
(A.44) |
である。
(A.43) 式は、 正則条件 (regularity conditions) と呼ばれるかなり 一般的な条件下で成り立つことがわかっている。この条件下では
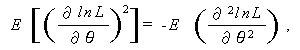
|
が成り立つので、(A.43) 式は
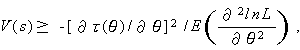
|
(A.45) |
とも書ける。
(A.43) 式の特別な場合は、τ(θ)=θ すなわち推定量 s が θ の不偏推定量の場合で、この時には、
|
が成り立つ。ここで、
|
は、標本における 情報量 (amount of information) と呼ばれる。この式から 明らかなように、推定量 s の最小分散限界は標本における情報量が増えると、 小さくなる。
MVB は、常に存在するとは限らないが、それより大きいところの最小分散 MV を持つ推定量は存在し、一意的に定まることがわかっている。この MV 推定量 (minimum variance estimator) は、近代的な意味での 有効推定量と言える。
正確には、
| 推定量 s は、母数 θ について、サンプルのすべての情報を含むとき、 充足性(十分性)がある、 |
という。また、そのような特性を持つ推定量は、 充足(十分)推定量 (sufficient estimator) と呼ばれる。
一般に、ある推定量が充足(十分)推定量であるかどうかの判定には、つぎの 分解基準 (factorization criterion) もしくは ネイマン基準 (the Neyman criterion) を用いる。
|
さて、母数 θ は θ=(θtr , θts)t な る列ベクトルとする。また、r \geq 1, s \geq 0$ であるとする。さらに、A.5.4 節 で述べた標本の尤度関数を
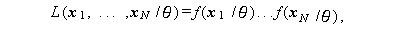
|
(A.49) |
とする。A.5.4 節では、標本はベクトル量でなくスカラー量であったことに注意せよ。
この時、帰無仮説
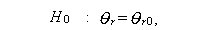
|
(A.50) |
を、対立仮説
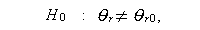
|
(A.51) |
に対して検定したいとする。うえの帰無仮説は、もし s =0 ならば単純仮説、 もし s \geq 1$ ならば、複合仮説である。
尤度比検定(likelihood ratio test) とは、一般につぎの尤度の比の 分布を用いて上述の帰無仮説を検定する方法である:
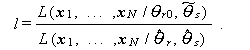
|
(A.52) |
ここで、分母は尤度
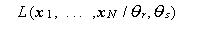
|
の無条件最大値を与える ML 推定量 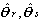 、
一方分子は (A.50) 式の帰無仮説が正しい時の尤度
、
一方分子は (A.50) 式の帰無仮説が正しい時の尤度
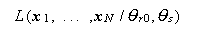
|
の、 θsの条件付き最大値を与える ML 推定量
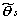 を
必要とする。
を
必要とする。
ただし、特定の場合を除き、一般的には尤度比の正確な分布はわかっていないので、
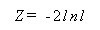
|
が帰無仮説のもとで、漸近的に自由度 r の χ2 -分布に従うことを利用し
て検定を行う。ここで、r は全母数 k =r + s から局外母数の数 s を差し引いた
ものである。
![]()
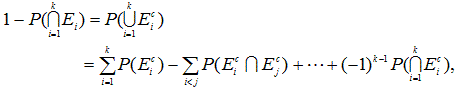
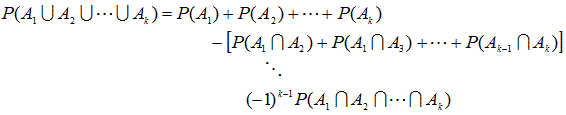
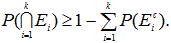
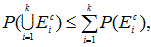
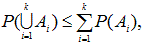
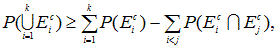
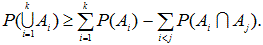
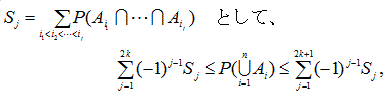
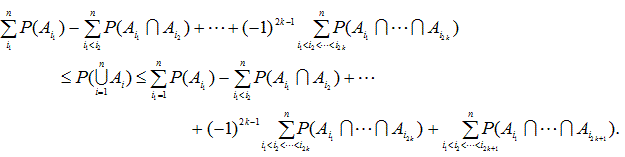
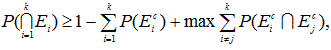
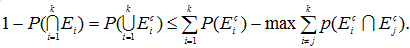
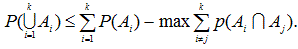
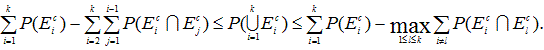
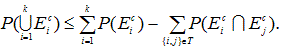
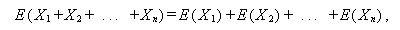
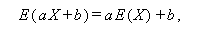
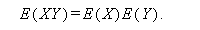
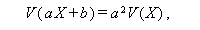
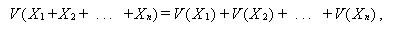
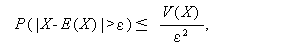
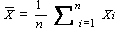 は、正規分布 N (μ ,σ2/n ) に従う。
は、正規分布 N (μ ,σ2/n ) に従う。
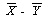 の分布は、
N (μx - μy ,σ2x /n +σ2y /m ) に従う。
の分布は、
N (μx - μy ,σ2x /n +σ2y /m ) に従う。
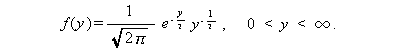
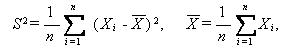
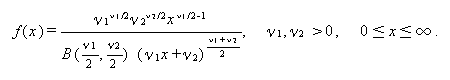
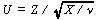 の密度
関数 f (u ) は、つぎの式で与えられる自由度 ν の t -分布に従う。
の密度
関数 f (u ) は、つぎの式で与えられる自由度 ν の t -分布に従う。
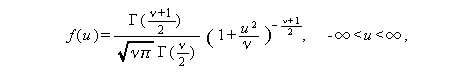
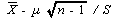 は、自由度 n -1 の t -分布に従う。
は、自由度 n -1 の t -分布に従う。