このページは、令和2年5月7日に一部更新しました。
われわれが予測ないしは説明したい複数の変数、すなわち 予測変数( predictor variables)でもって、ある変数(これは従属変数 dependent variable、 あるいは 基準変数 criterion variable と呼ばれる)の値の変動を予測 ないしは説明したいとする。この時、N 人の被験体のそれぞれに対し、両変数 の値を観測した結果は、Table 2.1 のように書ける。
| 基準変数の値 | m 個の予測変数の値 |
| y1 | x11 , x12 , ... , x1m |
| y2 | x21 , x22 , ... , x2m |
 |
... |
| yN | xN1 , xN2 , ... , xNm |
重回帰分析(multiple regression)では、このようなデータから出発して、 予測変数全体で、基準変数をどれ程説明できるか、及びもし予測ないし説明 できるとしたら、どの予測変数がどれほど基準変数を説明できるかなどを 検討する。
重回帰分析における変数は、予測変数、基準変数共に、通常は評定尺度や検査得点 のような間隔尺度レベルで測定されていなければならない。
分散分析における測定値を基準変数、これに影響するとみなし実験配置する要因 (処理)を予測変数とみなせば、分散分析と重回帰分析は、共に基準変数に対する 予測変数の効果の有無を検討する方法と言える。 一方、両者の相違点をあげれば、分散分析では予測変数をあらかじめできる限り 絞り込み、少数の変数(要因)についてその水準をカテゴリー化し、要因の水準の 組み合わせに対して被験者を無作為に割り付けるのを原則とするのに対して、重回 帰分析では予測変数はそれほど絞り込まず、通常はそれらの変数をカテゴリー化せず、 すべての被験者にすべての変数に対する測定を行うという点である。
Table2.2.は、この種の具体例を示す。データはA大学心理学科のある年度の C ゼミ の13名の受講生の卒業論文の成績及び1年次から3年次までの各学年での学業成績 (平均)である。このデータの分析の目的が、
| 学生 | 卒論 | 一年次 | 二年次 | 三年次 |
|---|---|---|---|---|
| 1 | 85 | 65 | 73 | 83 |
| 2 | 84 | 68 | 80 | 87 |
| 3 | 85 | 65 | 73 | 83 |
| 4 | 84 | 78 | 72 | 82 |
| 5 | 84 | 72 | 76 | 80 |
| 6 | 80 | 65 | 59 | 79 |
| 7 | 80 | 57 | 66 | 78 |
| 8 | 78 | 64 | 62 | 72 |
| 9 | 75 | 68 | 67 | 77 |
| 10 | 75 | 68 | 68 | 70 |
| 11 | 70 | 61 | 60 | 70 |
| 12 | 68 | 61 | 58 | 66 |
| 13 | 65 | 56 | 59 | 62 |
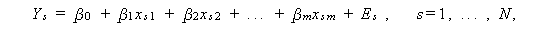
|
(2.1) |
と書かれる。ここで、 β0 ,β1 , ... ,βm は 回帰係数 (regression coefficients) と呼ばれる。 m ≧ 2 の時、これらは 偏回帰係数 (partial regression coefficients) と呼ばれる。また、Es は、誤差変動で、
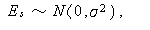
|
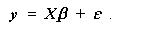
|
(2.2) |
|
y = (Y1 ,Y2 , ... ,
YN ) t,
| |

|
(2.3) |
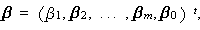
|
(2.4) |
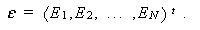
|
(2.5) |