| 3.1母集団の分布形が未知だが、母分散は既知で、 標本数が大の場合 |
| 3.2母集団の分布形が正規分布で、母分散は未知 の場合 |
| 3.3予習課題と予習箇所 |
| 3.4データ |
| 3.5目的 |
| 3.6注意事項 |
| 3.7問題 |
| 3.8区間推定の計算手順 |
| 3.9実習レポート記入の仕方 |
| 3.10 統計ソフト SAS を用いた母平均の区間推定計算プログラムの実行手順 |
このページは、令和2年5月6日に一部修正しました。
一般に、われわれが手にするデータ(標本)(例えば、ある錯視条件下で測定した ミラーリエル錯視における10名分の錯視量)が得られるもとの数値の集合のことを、 統計学では 母集団 (population、もしくは parent population) と呼ぶ。
このような数値の集まりは、一般には無数に考えられるので、 無限母集団 (脚注1) (infinite population) であり、実際にわれわれが手にするのはその集合のほんの一部 である。もっとも、統計学では標本は通常そのような数値の集合の中から作為なしに、 すなわち 無作為に (randomly) 抽出されると仮定する。
このようにして得られた N 個の標本から、どのようにして統計学ではそれが得ら れた母集団の分布の特徴、例えば平均(これを 標本平均 (sample mean) と区別 して 母平均 (population mean) と呼ぶ)を推定したり、当該標本がある母集団 からの無作為標本であるかどうかを検討(統計学では、このような標本をもとに母集団 の何らかの仮説の真偽を検討することを、 検定 (test) と呼ぶ)したりするので あろうか。本章では、これらの方法の基本的な考え方を学習し、さらに具体的な推定方 法、とりわけ母平均の 区間推定 (脚注2) (interval estimation) の方法を学ぶ。N 個の無作為標本から、それが得られた 母集団での平均、すなわち母平均を区間推定するに際しての基本的な考え方はつぎの 通りである:
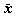 と表そう。もちろんこれは、
と表そう。もちろんこれは、
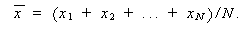
|
(3.1) |
とは異なる標本平均
' が得られよう。
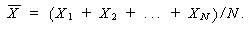
|
(3.2) |
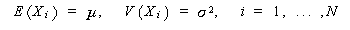
|
(3.3) |
重要な点は、われわれはこの時点では母集団の平均や分散の議論はしているが、
母集団の分布形については 何ら仮定していないという点
である。いずれにせよ、この時確率変数 X 1 , X 2 , ... , X N は、互いに独立
であると仮定すれば、標本変量平均の平均 E (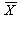 ) および標本変量平均の分
散 V () は、それぞれつぎのように書ける:
) および標本変量平均の分
散 V () は、それぞれつぎのように書ける:
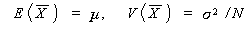
|
(3.4) |
つまり、標本変量平均の平均は母平均に、標本変量平均の分散は母分散の 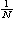 に、それぞれなることがわかる。
に、それぞれなることがわかる。
前節の議論から、母集団の分布形がわからなくても、標本数が大であれば、母集団 から無作為抽出された N 個の標本を考える時、標本変量平均は、近似的に (3.4) 式で与えられる平均と分散を持つ正規分布に従うことがわかった。この結果を利用する と、われわれはつぎのようにして標本平均からそれが得られた母集団の平均がどれくら いの値になるかを区間推定することができる。
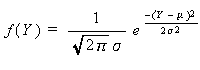
|
(3.5) |
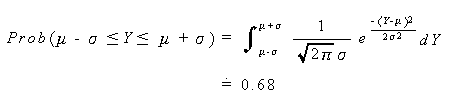
|
(3.6) |
この結果は、正規分布に従う確率変数の値がその分布の平均マイナス1標準偏差から平 均プラス1標準偏差の間に入る確率がおよそ 0.68 もしくは68パーセントであるこ とを意味する。同様に、
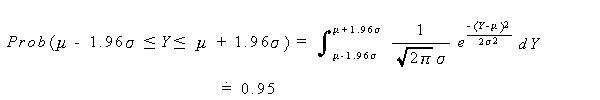
|
(3.7) |
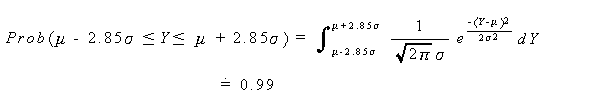
|
(3.8) |
に当てはめてみ
よう。この変数は、近似的には正規分布に従うので、Y = とみなすと、その
平均及び分散は、もとの標本変量 X i , i =1, ... , N の平均が μ0 で
分散が σ02 と仮定すると、先程の議論からそれぞれ μ0 及び
σ02 / N なので、例えば (3.7) から、つぎの結果が導かれる:
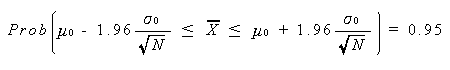
|
(3.9) |
(3.9) 式は、μ0 について書き直すと、つぎのようになる:
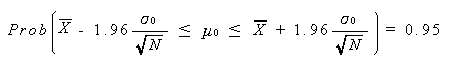
|
(3.10) |
(3.10) 式の は実際には観測されないので、これをその実現値としての
と置き換えると、次式が得られる:
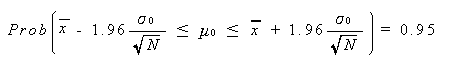
|
(3.11) |
この式は、母集団の分布形が未知の時、大サンプルデータから、それが得られた母集団 の平均を標本平均と母集団の分散(標準偏差)及び標本数の言葉で区間推定する公式を 与えている。この場合の 0.95 は、母平均が (3.11) 式の左辺の下限値から上限値に 入る可能性が95パーセントあることを意味しており、一般には信頼区間の 信頼 度(あるいは、 信頼率、または 信頼係数)(confidence coefficient) と 呼ばれる。また、(3.11) 式の左辺の下限値や上限値は一般に 信頼限界 (confidence limits) と呼ばれる。
(3.11) 式は、より一般的には信頼度を 1- α として(例えば、(3.11) 式では この α は、0.05)、つぎのように書ける:
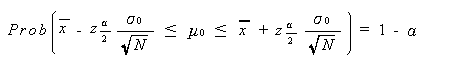
|
(3.12) |
ここで、z 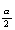 は、
標準正規分布 (standard normal
distribution)(脚注4)
の上側 100
は、
標準正規分布 (standard normal
distribution)(脚注4)
の上側 100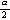 パーセント点で、つぎのように定義される:
パーセント点で、つぎのように定義される:
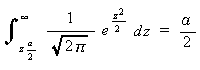
|
(3.13) |
前節では、われわれがある母集団から大標本を得たとき、その平均を用いて母集団の 平均の区間推定を行う方法を学んだ。この節では、前節で導かれた式を異なる角度から 見直すと、手にした大標本がある特定の平均を持つ母集団からの標本であると言えるか どうかの検定に使えることを示す。
そのために、まず前節の (3.9) 式をつぎのように書き換えてみよう:
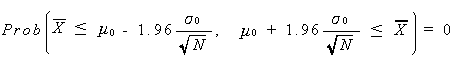
|
(3.14) |
この式は、もしわれわれが母平均 μ0 で母分散 σ02 なる母集団から 大標本を手にしたとすれば、その平均が (3.14) 式の左辺の不等式で表される範囲の 値をとることは、同様な標本抽出を100回繰り返したとしても5回ほどしか得られ ないような希なことである、ということを言っている。
この結果を利用すると、われわれは母平均が未知のある母集団から大標本を手にした
時、その標本がある母平均 μ = μ0 を持つ母集団からの標本と言えるかどうかを
検定することができる。すなわち、われわれは標本から標本平均 を計算し、
それが (3.14) 式の左辺の区間に入っているならば、標本は μ = μ0 を母平均に
持つ母集団からの標本ではないと、もし入っていないならば標本は μ = μ0 を母
平均に持つ母集団からの標本であると、結論づければよい。ただし、この場合
母集団の分散 σ02 は既知であるという仮定がいることに注意
せよ。ここで、このような文脈での μ = μ0 のことを、統計学では一般に
帰無仮説 (null hypothesis) と呼ぶ。
上の検定は、より一般的には (3.12) 式を書き換えて、つぎのように帰無仮説を検 定することに等しい:
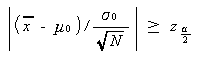
|
ならば、帰無仮説 H 0 : μ = μ0 を 棄却 (reject)、さもなければ 採択 (accept) する。ここで、もし標本平均が (3.12) 式の左辺の範囲に入った時、 そのようなことは 100 回の同様なサンプリングで 100α 回ぐらいしか 起こらないと言う意味で稀である、との理由で帰無仮説 H 0 : μ = μ0 を棄却す ると、もし帰無仮説が正しい場合には判断の誤りを犯す危険性があるので、統計学では この α のことを、 危険率 (level of significance、または significance level) と呼ぶ。危険率は、 有意水準 と呼ばれることもある。
また、上の式の中の
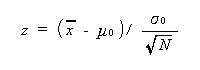
|
(3.15) |
のような検定に用いられる量は、 検定量 (test statistic) と呼ばれる。一般的 には、統計量を検定の目的で用いる場合、検定量と呼ぶ。うえの議論から明らかなよう に、z は近似的に標準正規分布に従う。
![]()
3.1 節では、母集団分布は未知でよいが、母分散がわかっていないといけなかった。 しかし、現実のデータの場合、母分散がわかっていない場合が多い。そのような場合 には、3.1 節の公式を利用することができない。そのような場合、母集団に正規分布 の仮定をおけば、われわれは 3.1 節と同様に母集団の平均の区間推定や、標本がある 平均を持つ母集団からのサンプルであると言えるかどうかの検定を行うことができる。
この場合の統計量は、前節 (3.15) 式の z ではなく、つぎの t で与えられる:
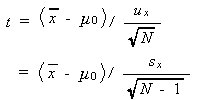
|
(3.16) |
ここで、u x は標本不偏標準偏差を、s x は標本標準偏差を表す。うえで定義さ れる統計量 t は、 t - 分布 として知られている。t - 分布の密度関数 は、つぎの式で表される:
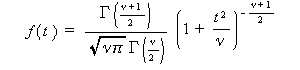
|
(3.17) |
ν は 自由度 (degree of freedom) と呼ばれ、ここでは t 分布の形を決定 するパラメータである。自由度 ν の t 分布は、t ν と書くことが多い。
この場合の、標本平均から母平均を区間推定する式は、つぎのようになる:
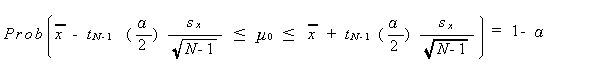
|
(3.18) |
ここで、 t N -1 () は、自由度 ν = N -1 の t -分布の
上側 100 パーセント点に対応する t の値であり、つぎのよう
にして定義される:
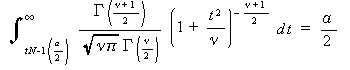
|
(3.19) |
![]()
![]()
データは、つぎのようなものである:
この場合、データはある無限母集団から無作為に抽出されたつぎのような大標本 で、母集団の分布形は未知とする。ただし、母集団の分散は分かっているものとする。 母集団の標準偏差が、当日配布する各人の問題用紙の中にある:
|
当日配布の標本数は40である。
この場合、データはある無限母集団から無作為に抽出されたつぎのような標本で、 母集団の分布形は正規分布とする。ただし、母集団の分散は未知とする。
|
当日配布の標本数は20である。
![]()
無限母集団からの無作為標本(N 個を手にしたとき、標本が得られた母集団の (母)平均の区間推定の方法を学ぶ
![]()
データが得られた母集団の分布形は未知か既知か、母分散は既知かどうか、標本数は 大か否か、に注意せよ。それにより、検定方式を変える必要がある。
![]()
手計算で、各人に配布する20個ないしは40個のデータから、標本が得られた母 集団の平均の、指定された信頼度の信頼区間を求めよ
![]()
区間推定の計算手順は、以下に示すように、3.1 節の、母集団の分布形が未知の場 合と 3.2 節の、母集団の分布形が正規分布の場合で一部異なるので注意せよ。
ここでは、3.1 節のケース、すなわち母集団の分布形は未知で、母分散 σ2 が既知で標本数が大の場合に、N 個の無作為標本を手にしたとき標本が得られたもと の母集団の平均の区間推定を行う計算の手順について述べる。母集団の分 散の情報については、当日配布する各人の問題用紙の中に記されている母標準偏差 σ0 の値を読みとること。計算の手順はつぎの通りである:
を求める。
 を計算する。
は、岩原の数表を見てもよい。
の値は、問題用紙で指定された信
頼度に対応するものを選ばねばならないことに注意せよ)。
を計算する。
は、岩原の数表を見てもよい。
の値は、問題用紙で指定された信
頼度に対応するものを選ばねばならないことに注意せよ)。
ここでは、3.2 節のケース、すなわち母集団の分布形は正規分布で、母分散 σ2 が未知の場合に、N 個の無作為標本を手にしたとき標本が得られたもと の母集団の平均の区間推定を行う計算の手順について述べる。計算の手順はつぎの通 りである:
を求める。
 を計算する。
は、岩原の数表を見てもよい。
の値は、問題用紙で指定された信
頼度と自由度に対応するものを岩原の付録の数表 (p.434) の必要個所を見て読み取ら
ねばならないことに注意せよ)。
を計算する。
は、岩原の数表を見てもよい。
の値は、問題用紙で指定された信
頼度と自由度に対応するものを岩原の付録の数表 (p.434) の必要個所を見て読み取ら
ねばならないことに注意せよ)。
![]()
この節の場合、3.2 節の「母集団の分布形が正規分布の場合」のみとするので、注 意せよ。
以下の項目について、すべて小数第3位を四捨五入して、小数第2位までの数値を 出席カードの裏側に順に書き写せ。その際、一行一項目とし、1. 平均 32.50 のよ うに書くこと。
)
![]()
以下の例は、国際的な統計ソフト SAS を用いた母平均の区間推定の計算の手順 を示す。
ここでは、N 個のデータの平均、標準偏差、及び母平均の区間推定の計算のため の SAS プログラムを紹介する。SAS を実行する手順を示す前に、ここで利用する データと出力結果の一部、及びそのための SAS プログラムを紹介する。ここでは、 第3章の 3.2 節、すなわち母集団の分布形が正規分布で、母分散は未知の場合に ついてのみプログラムと出力結果を示す。
| 3.10.1データ例 |
| 3.10.2出力結果の例 |
| 3.10.3SAS プログラムの例 |
| 3.10.4SAS による具体的手順 |
つぎのデータは、ここでは、心理統計学のテキストの乱数表から取った10個の架空の データである。
1 10 2 96 3 26 4 12 5 97 6 18 7 96 8 57 9 15 10 54 |
学生諸君は、この表の中から、各自の通し番号に対応する箇所から、縦に見て続け て10個を各ページから取り出し、IT センターの各自でログインした時の z ドライ ブの下の My Documents -> SASUniversityEdition -> myfolders の下の data フォル ダの中に、TeraPad を用いてファイル名 interval_est.txt なる名前をつけてうえの例のように入力し保存すること。 その際、「名前をつけて保存」画面で、必ずファイル名 の下のファ イルの種類は「テキストファイル(*.txt)」を選択する こと。
ここで、うえの10個のデータの各行は10人の被験者に対応し、各行とも最 初の2桁の数値が被験者番号を、1つ空白を置き2桁で打ってあるのが、 何らかの心理テストの得点であるとする。もちろん、データはすべて全角ではなく、 半角で入力せよ。
学籍番号に対応する各人のデータの先頭は、各ページごと、左上から下に向かって 2桁の数値を5つづつ飛ばして到達する位置とする。各列の最後に来たら、次の列の先 頭に戻りカウントすること。
例えば、学籍番号 001 の学生は、p.445 の数値の左最上部の数値から始め、94, 18, ..., 06, 63 の10個をデータとして、上記データファイルに入力する。
また、例えば学籍番号 012 の学生ならば、p.445 の数値左最上部から2列目の6つ目 の数値から始め、81, 18, ..., 78, 03 の10個をデータとして、データファイルに 入力する。
以下の計算結果は、後続の SAS プログラムよって得られたものである。
Some statistics on a set of data 1
2007年06月07日 木曜日 午前08時27分01秒
UNIVARIATE プロシジャ
変数 : x (mark of a test)
モーメント
N 10 重み変数の合計 10
平均 48.1 合計 481
標準偏差 35.1267704 分散 1233.89
歪度 0.37137465 尖度 -1.5340217
無修正平方和 35475 修正済平方和 12338.9
変動係数 73.0286287 平均の標準誤差 .
基本統計量
位置 ばらつき
平均 48.10000 標準偏差 35.12677
中央値 40.00000 分散 1234
最頻値 96.00000 範囲 87.00000
四分位範囲 81.00000
位置の検定 H0: Mu0=0
検定 --統計量--- -------p 値-------
符号検定 M 5 Pr >= |M| 0.0020
符号付順位検定 S 27.5 Pr >= |S| 0.0020
分位点 ( 定義 5 )
分位点 推定値
100% 最大値 97.0
99% 97.0
95% 97.0
90% 96.5
75% Q3 96.0
50% 中央値 40.0
25% Q1 15.0
10% 11.0
5% 10.0
1% 10.0
0% 最小値 10.0
極値
---最小値--- ---最大値---
値 Obs 値 Obs
10 1 54 10
12 4 57 8
15 9 96 2
Some statistics on a set of data 2
2007年06月07日 木曜日 午前08時27分01秒
UNIVARIATE プロシジャ
変数 : x (mark of a test)
極値
---最小値--- ---最大値---
値 Obs 値 Obs
18 6 96 7
26 3 97 5
print the mean, std, and the confidence limits 3
2007年06月07日 木曜日 午前08時27分01秒
OBS noss xmean xstd l_int u_int
1 10 48.1 35.1268 21.6144 74.5856
|
うえの出力結果のうち、最初の部分はのちに示す SAS プログラムによる univariate プロシジャの出力結果で、諸君が手計算で行なった平均、標準偏差、 分散以外にも多くの基礎的なデータの統計量が計算されていることがわかる。 出力の最後の行が、それらの結果のうちの幾つかと、さらに授業時に指定 された信頼度での平均の信頼区間の下限値と上限値を示す。出力は左端から順に、 OBS、noss(標本数)、xmean(平均)、xstd(標準偏差)、l_int(信頼区間下 限値)、及び u_int(信頼区間上限値)である。最初の OBS の値 1 は、SAS 独特の出力によるもので、諸君の計算結果にはかかわりないので、無視せよ。 いずれにせよ、これらの値を、諸君の授業中に手計算した結果と比較し、手計算 が間違っていたならば、うえの結果と一致するまで各自で計算のし直しをして おくこと。そうしないと、定期試験で合格点が取れないであろう。
![]()
上記のような出力結果を手にするためには、SAS の場合、まずデ ータに変数情報等を付けて特定のフォルダに保存しておくことはせず、それを SAS プログラムの中に入れておいて、そのまま特定のプロシジャ、例えば univairate プロシジャで分析するのが簡単である。
しかし、ここでは諸君にとって初めての SAS プログラムによる宿題なので、よ り一般的な大サンプルの場合に便利な方法として、あらかじめデータのみを data フォルダに保存しておいて、それをプログラム中から呼び出して特定のプロシジ ャで分析するやり方を勉強することにする。以下には、そのための SAS プログラ ムを示した。
このやり方の場合も、実はいろいろなやり方で最終的な結果を得ることが可能で ある。1つは、data フォルダに保存されたデータを呼び出して、データのそれぞれ に変数情報等をつけて、一旦 SAS に特有の「永久 SAS ファイル」というファイルに それらの情報を保存した上で、改めて別のプログラムにより必要なデータの分析を 行なう方法である。他方は、これらの2ステップを1つのプログラム上で行なって しまう方法である。この場合は、変数情報を付与されたデータは、SAS では「一時 SAS ファイル」という名前の一時的なファイルに保存されるが、この種のファイル はセッションが終了すると消えてしまうファイルである。
ここでは、データの変数情報の付与の後、同一プログラム内でこれらの統計量 を計算するプログラムにした。プログラム名は、interval_est.sas とする。
*-------------------------------------------------------------------------* | February 2, 2016 | | file name: interval_est.sas | | | | a sasprogram for computing some basic statistics as well as confidence | | interval of a mean at a specified confidence level from a set of data. | | | *-------------------------------------------------------------------------*; filename data "/folders/myfolders/data/interval_est.txt"; options ps=60; data work1; infile data; input ssno 2. x 3.; label ssno='subject number' x='mark of a test'; run; title 'Some statistics on a set of data'; proc univariate data=work1 vardef=n; var x; output out=work2 n=noss mean=xmean std=xstd; run; title 'compute the confidence interval of a mean'; data work3; set work2; *---------------------------------------------------------- | つぎの tpoint は、授業中に示した信頼度 1-α の場合の、t-分布表の自 | 由度ν=N-1 の場合の危険率 P=α に対応する値であり、例えば千野テキスト | の pp.118-119 の t-分布表から読み取ること。以下の 2.262 は、N=10 | (自由度は ν=9)で、信頼度 1-α =0.95、すなわち p=α=0.05 に対応す | る値であることに注意。必要な場合、この修正を行うこと。 *----------------------------------------------------------; tpoint=2.262; aterm=tpoint*xstd/sqrt(noss-1); l_int=xmean-aterm; u_int=xmean+aterm; run; title 'print the mean, std, and the confidence limits'; proc print data=work3; var noss xmean xstd l_int u_int; run; |
*-------------------------------------------------------------------------* | June 7, 2007 | | file name: interval_est.sas | | | | a sasprogram for computing some basic statistics as well as confidence | | interval of a mean at a specified confidence level from a set of data. | | | *-------------------------------------------------------------------------*; filename data "p:\data\interval_est.txt"; options ps=60; data work1; infile data; input ssno 2. x 3.; label ssno='subject number' x='mark of a test'; run; title 'Some statistics on a set of data'; proc univariate data=work1 vardef=n; var x; output out=work2 n=noss mean=xmean std=xstd; run; title 'compute the confidence interval of a mean'; data work3; set work2; *---------------------------------------------------------- | つぎの tpoint は、授業中に指示した信頼度 1-alpha の場合 | の、t-分布表の自由度 nu=N-1 の場合の危険率P=alpla に対 | 応する値であり、例えば千野テキストの pp.118-119 の t- | 分布表から読み取ること。以下の 2.262 は、N=10(自由度は、 | nu/=9)で信頼度 1-alpha=0.95、すなわち P=alpha=0.05 に対 | 応する値であることに注意。必要な場合、この修正をせよ。 *----------------------------------------------------------; tpoint=2.262; aterm=tpoint*xstd/sqrt(noss-1); l_int=xmean-aterm; u_int=xmean+aterm; run; title 'print the mean, std, and the confidence limits'; proc print data=work3; var noss xmean xstd l_int u_int; run; |
![]()
以下のプログラムと、具体的手順は、平成28年度からの SAS 無償バージョン用のもの である。
| interval_est.sas |
![]()