| 6.1データ |
| 6.2目的 |
| 6.3注意事項 |
| 6.4問題 |
| 6.5予習課題と予習箇所 |
| 6.6相関係数の計算手順 |
| 6.7相関係数とその検定公式 |
| 6.8実習レポートの記入の仕方 |
| 6.9 統計ソフト SAS を用いた相関係数の計算及び検定の実行手順 |
このページは、平成14年6月1日に開設しました。
このページは、令和2年5月6日午後に一部更新しました
この章では、2組の定量的変数間の直線的関係の強さを表す指標であるピアソンの 偏差積率相関係数 (Pearson's product-moment coefficient of correlation)(略して 相関係数と呼ばれる)の計算方法と、その有意性検定の方法を学ぶ。
教育や心理の分野では、しばしば被験者は多くのアンケート項目や検査項目に回答 したり、複数の実験条件に対して反復測定を受ける。このような場合、測定値間には 一般にある種の関連が生じる。測定値がすべて間隔尺度以上のレベルであれば、それ らのうちの任意の2組の測定値を取り上げ、平面上に被験者の各々を点として位置づけ ると、2組の変量間には直線的な関係や曲線的な関係などを読みとることができる。 それらの定量的関係のうち、とりわけ直線的関係の強さを表す指標が相関係数である。
相関係数の統計的有意性の検定法方は、サンプル数の多少により異なる。ここでは、 サンプル数が小さい場合の検定の手続きを学ぶ。
例えばデータは、N 人の被験者の YG 性格検査の抑うつ性と気分の変化の得点で あるとする。一般的には、それらは以下のように書ける:
|
当日の問題の標本数 N は20である。
小標本の対データから、2組の定量変数間のピアソンの相関係数を求め、さらに その統計的有意性の検定を行う。
なし
卓上計算機を用い、小標本の対データから 散布図 (scatter diagram) を作成し、さらに標本相関係数の計算とその統計的有意性 の検定を行え。
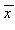 及び
及び 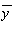 を求める。
を求める。
![]()
まず、相関係数は次式で求める:
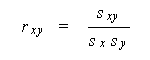
|
(6.1) |
ここで、(6.1) 式の分子の共分散は、次式で与えられる:
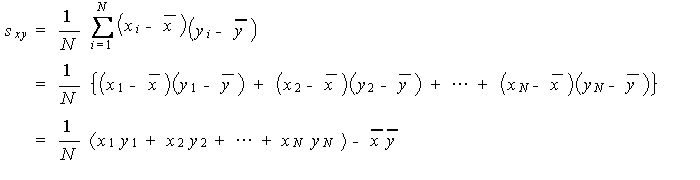
|
(6.2) |
相関係数の推定・検定は、一般的につぎのようにして行う。
サンプル数が小さい時には、母集団の相関係数 ρ がゼロなる帰無仮 説 H0: ρ =0 のもとで、標本相関係数から作るつ ぎの量 t
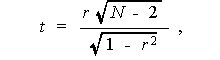
|
(1.5) |
が、自由度 ν =N -2 の t -分布に従うことを利用する。
(註1)この式は、Fisher (1915) による相関係数の分布の一般形の(母相関 がゼロの)特殊ケースである(例えば、Kendall and Stuart, 1973, Vol.1, p.415)。
この場合は、r が大で母相関係数がゼロならば、r は近似的に平均ゼロ なる正規分布に従うことを利用する。この時、r の標準誤差は 1/sqrt(N) である (McNemar, 1969)。
(註2)r の分散(標準誤差の二乗)の一般形は知られている(例えば、 Kendall and Stuart, 1973, Vol.1, p.251) が、McNemar によるそれは、 r の分散の一般形で、分布が2変量正規分布かつ母相関係数がゼロの場合 にあたる。
母相関係数が任意の場合、その信頼限界の推定や検定には、標本相関係 数を z 変換(Fisher, 1921)
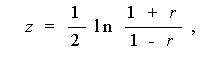
|
(6.4) |
し、さらに
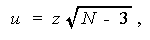
|
(6.5) |
とした時の u が、近似的に正規分布に従うことを利用する。
(註3)任意の母相関係数の場合の相関係数 r の(標本)分布の正確な形(一般 に は正規分布ではない)は、Fisher (1915) が示しており複雑な分布関数の形を してい る(同上、Kendall & Stuart, 1973, Vol.2, p.415)。
![]()
![]()
これまで、手計算による相関係数とその検定の計算方法について述べてきたが、 サンプル数が大きくなると、たいへんな手間がかかる。このような作業は 本来人間には向かない。原理さえわかれば、諸君は今やこの種の検定を手計算 でやる時代ではない。以下の2つの例は、国際的な統計ソフト SAS を用いた 相関係数とその検定の手順を示す。
ここでは、相関係数の計算と検定を行うための SAS プログラムを紹介する。 SAS を実行する手順を示す前に、ここで利用するデータと出力結果の一部、及び そのための SAS プログラムを紹介する。
| 6.9.1.1データ例とその入力方法 |
| 6.9.1.2出力結果の例 |
| 6.9.1.3SAS プログラムの例 |
| 6.9.1.4SAS による具体的手順 |
つぎのデータは、ここでは、心理統計学のテキストの乱数表から取った架空 のデータである。
1 10 10 2 96 76 3 26 61 4 12 15 5 97 40 6 18 17 7 96 14 8 57 03 9 15 14 10 54 55 11 12 83 12 48 79 13 37 20 14 34 67 15 65 10 16 25 75 17 46 06 18 45 07 19 12 98 20 46 71 |
学生諸君は、心理統計学テキストの付録の表の中から、各自の通し番号に対応する箇所から、 縦に見て続けて20個を各ページから取り出し、ecip の z ドライブの My Documents -> SASUniversityEdition -> myfolders の下の data フォルダの中にTeraPad を用いてファイル名 corr_scatter.txt なる名前を付けてうえの例のように保存すること。
ここで、うえの20個のデータの各行は20人の被験者に対応し、各行とも最 初の2桁の数値が被験者番号を、1つ空白を置き2桁で打ってあるのが、p.445 の 各自の学籍番号に対応する20個の値、さらに1つの空白を置き2桁で打ってある のが、p.446 の各自の学籍番号に対応する20個の値であるとする。もちろん、デ ータはすべて全角ではなく、半角で入力せよ。また、被験者番 号が9番までの被験者の被験者番号は、半角スペースを1つ入れた後一桁の被験者 番号を上の例のように入力すること。
学籍番号に対応する各人のデータの先頭は、各ページごと、左上から右下に向かって 2桁の数値を5つづつ飛ばして到達する位置とする。各列の最後に来たら、次の列の先 頭に戻りカウントすること。
例えば、学籍番号 001 の学生は、p.445 の数値の左最上部の数値から始め、94, 18, ..., 90, 35 までを20名の被験者の第1変数の20個のデータとし、p.446 の数値 の左最上部の数値 70, 99, ..., 95, 45 までの20個のデータを20名の被験者の 第2変数の20個のデータとして、上記データファイルに上の例のように2変数が 対になる形に入力する。
また、例えば学籍番号 012 の学生ならば、p.445 の数値左最上部から2列目の6つ目 の数値から始め、81, 18, ..., 29, 38 を第1変数のの20個のデータ、p.446 の数 値の左最上部から2列目の6つ目の数値から始め、96, 62, ..., 29, 61 を第2変数 の20個のデータとして、入力する。
以下の検定結果は、後続の SAS プログラムよって得られたものである。 以下の出力中、標準偏差は SAS では不偏標準偏差であり、サンプル数で割るところの元の標 準偏差とは異なるので、注意せよ。また、以下の出力結果には、相関係数 (この例では、 -0.08693) と p-値 (この例では、0.7155) は示されているが、 相関係数の検定のための t 値は出力されていないので、注意せよ。 そこで、検定結果は p-値が 0.05 より大きい場合、採択、0.05 以下の 場合、棄却、と判断し、授業中で手計算した t 値と千野の心理統計テキストの数値表から 判断した「採択または棄却の判断」と比較せよ。
correlation and test of the null hypothesis about it
CORR プロシジャ
2 変数 : x y
要約統計量
変数 N 平均値 標準偏差 合計 最小値 最大値 ラベル
x 20 42.55000 28.55185 851.00000 10.00000 97.00000 the first quantitative variable
y 20 41.05000 32.37035 821.00000 3.00000 98.00000 the second quantitative variable
Pearson の相関係数, N = 20
帰無仮説 Rho=0 に対する Prob > |r|
x y
x 1.00000 -0.08693
the first quantitative variable 0.7155
y -0.08693 1.00000
the second quantitative variable 0.7155
プロット : y*x. 凡例 : A = 1 OBS, B = 2 OBS, ...
|
|
100 +
| A
|
|
t |
h |
e |
| A
s 80 + A
e |
c | A A
o |
n | A
d | A
|
q |
u 60 + A
a |
n | A
t |
i |
t |
a |
t |
i 40 + A
v |
e |
|
v |
a |
r |
i |
a 20 + A
b | A
l | A A A
e |
| A A
| A
| A
| A
0 +
|
---+----------+----------+----------+----------+----------+----------+----------+----------+----------+--
10 20 30 40 50 60 70 80 90 100
the first quantitative variable
|
![]()
平成28年度からは、つぎの2種類のプログラムの中の最初の SAS 無償バージョン用の プログラムを用いること。
*-------------------------------------------------------------------------*
| February 2, 2016 |
| |
| a sasprogram for computing the correlation coefficient and testing the|
| null hypothesis about it. |
| |
*-------------------------------------------------------------------------*;
filename data '/folders/myfolders/data/corr_scatter.txt';
options ps=60;
data work;
infile data;
input ssno 2. (x y) (3.);
label ssno='sample number'
x='the first quantitative variable'
y='the second quantitative variable';
run;
title 'correlation and test of the null hypothesis about it';
proc corr data=work;
var x y;
run;
title 'scatter diagram of the two variable, x, y';
proc plot data=work;
plot y*x;
run;
|
脚注1 : マイナス記号は、同一列内の数字 0 と 1 を同時マークせよ
![]()
(2) 平成27年度まで導入されていた SAS バージョン 9.4 等でのプログラム
*-------------------------------------------------------------------------*
| March 27, 2004 |
| |
| a sasprogram for computing the correlation coefficient and testing the|
| null hypothesis about it. |
| |
*-------------------------------------------------------------------------*;
filename data 'p:\data\corr_scatter.txt';
options ps=60;
data work;
infile data;
input ssno 2. (x y) (3.);
label ssno='sample number'
x='the first quantitative variable'
y='the second quantitative variable';
run;
title 'correlation and test of the null hypothesis about it';
proc corr data=work;
var x y;
run;
title 'scatter diagram of the two variable, x, y';
proc plot data=work;
plot y*x;
run;
--- 架空データを用いた、相関係数とその検定のためのプログラム ---
![]()
6.9.1.4 SAS による具体的手順
![]()
corr_scatter.sas
![]()
![]()
脚注
![]()