| 1.1データ |
| 1.2目的 |
| 1.3注意事項 |
| 1.4問題 |
| 1.5計算公式 |
| 1.6予習課題と予習箇所 |
| 1.7実習レポート記入の仕方 |
| 1.8 統計ソフト SAS を用いた平均・分散等計算プログラムの実行手順 |
| 1.9 統計ソフト SPSS を用いた平均・分散等計算プログラムの実行手順 |
このページは、令和2年5月5日に一部修正しました。
A 大学文学部心理学科1年生全員の身長データから N =10 名をでたらめに(ランダ ム)に抜き取ったもの
|
少数データの 平均 (mean) と 標準偏差 (standard deviation) の求め 方を学習する
手計算で、各人が岩原教科書から転記する少数データの平均、 分散 (variance)、 不偏 分散 (unbiased estimate of variance)、と標準偏差を計算せよ
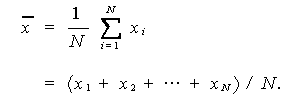
|
(1.1) |
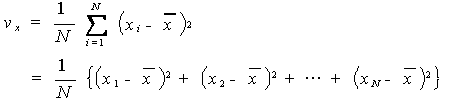
|
(1.2) |
ただし、卓上計算機で分散を求めるには、上式をつぎのように変形したものを 用いるのが便利であるし、計算間違いし難い:
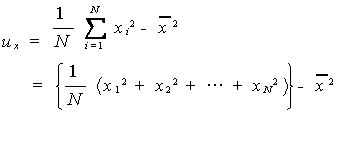
|
(1.3) |
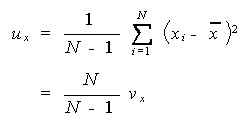
|
(1.4) |
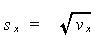
|
(1.5) |
- 1. 名義、順序、間隔、比率尺度について
- 岩原(著)教育と心理のための推計学/ 第1章 1.3 節 四種の測定尺度
- 2. 平均と標準偏差について
- 岩原(著)教育と心理のための推計学/ 第4章 4.1 節 代表値とは何か、4.4 節 算術平均、第5章 5.1 節 散布度とは何か、5.5 節 標準偏差
以下の項目について、すべて小数第3位を四捨五入して、小数第2位までの数値を出席 カードの裏側に順に書き写せ。その際、一行一項目とし、1. 平均 32.50 のように書く こと。
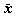 )
)
これまで、手計算による N 個のデータの平均、分散、不偏分散、標準偏差の計算 方法について述べてきたが、サンプル数が大きくなると、たいへんな手間がかかる。 このような作業は本来人間には向かない。原理さえわかれば、諸君は今やこの種の 作業を手計算でやる時代ではない。以下の例は、国際的な統計ソフト SAS を 用いた平均、分散等の計算の手順を示す。
ここでは、N 個のデータの平均、分散、不偏分散、標準偏差の計算のための SAS プログラムを紹介する。SAS を実行する手順を示す前に、ここで利用するデータと出 力結果の一部、及びそのための SAS プログラムを紹介する。
| 1.8.1.1データ例 |
| 1.8.1.2出力結果の例 |
| 1.8.1.3SAS プログラムの例 |
| 1.8.1.4SAS による具体的手順 |
つぎのデータは、ここでは、心理統計学のテキストの乱数表から取った10個の架空の データである。
1 10 2 96 3 26 4 12 5 97 6 18 7 96 8 57 9 15 10 54 |
学生諸君は、この表の中から、各自の通し番号に対応する箇所から、縦に見て続け て10個を各ページから取り出し、情報処理教育センター(以降、ecip と省略する)の 各自でログインした時の z ドライブの下の My Documents -> SASUniversityEdition -> myfolders の下の data フォルダの中に、TeraPad を 用いてファイル名 basic_stat.txt なる名前をつけてうえの例のように入力し保存す ること。その際、「名前をつけて保存」画面で、ファイル名 の下 のファイルの種類は「テキストドキュメント- MS-DOS 形式」を選択する こと。
平成28年度現在、SAS は情報処理教育センターの、第1及び9クライアント室で利用 できるが、学生諸君は通常は(授業の入っていない一般利用 用に開放されている)第1クライアント室で SAS を使うこと。
ここで、うえの10個のデータの各行は10人の被験者に対応し、各行とも最 初の2桁の数値が被験者番号を、1つ空白を置き2桁で打ってあるのが、 何らかの心理テストの得点であるとする。もちろん、データはすべて全角ではなく、 半角で入力せよ。
学籍番号に対応する各人のデータの先頭は、各ページごと、左上から下に向かって 2桁の数値を5つづつ飛ばして到達する位置とする。各列の最後に来たら、次の列の先 頭に戻りカウントすること。
例えば、学籍番号 001 の学生は、p.445 の数値の左最上部の数値から始め、94, 18, ..., 06, 63 の10個をデータとして、上記データファイルに入力する。
また、例えば学籍番号 012 の学生ならば、p.445 の数値左最上部から2列目の6つ目 の数値から始め、81, 18, ..., 78, 03 の10個をデータとして、データファイルに 入力する。
以下の計算結果は、後続の SAS プログラムよって得られたものである。
Some statistics on a set of data
UNIVARIATE プロシジャ
変数 : x (mark of a test)
モーメント
N 10 重み変数の合計 10
平均 48.1 合計 481
標準偏差 37.0268671 分散 1370.98889
歪度 0.44039616 尖度 -1.7476455
無修正平方和 35475 修正済平方和 12338.9
変動係数 76.9789337 平均の標準誤差 11.7089235
基本統計量
位置 ばらつき
平均 48.10000 標準偏差 37.02687
中央値 40.00000 分散 1371
最頻値 96.00000 範囲 87.00000
四分位範囲 81.00000
位置の検定 H0: Mu0=0
検定 --統計量--- -------p 値-------
Student の t 検定 t 4.107978 Pr > |t| 0.0026
符号検定 M 5 Pr >= |M| 0.0020
符号付順位検定 S 27.5 Pr >= |S| 0.0020
分位点 ( 定義 5 )
分位点 推定値
100% 最大値 97.0
99% 97.0
95% 97.0
90% 96.5
75% Q3 96.0
50% 中央値 40.0
25% Q1 15.0
10% 11.0
5% 10.0
1% 10.0
0% 最小値 10.0
極値
---最小値--- ---最大値---
値 Obs 値 Obs
10 1 54 10
12 4 57 8
15 9 96 2
18 6 96 7
26 3 97 5
print the mean, var, u_x, and std
OBS noss xmean xvar u_x xstd
1 10 48.1 1233.89 1370.99 35.1268
|
うえの出力結果のうち、最初の部分はのちに示す SAS プログラムによる univariate プロ シジャの出力結果で、諸君が手計算で行なった平均、標準偏差、分散以外にも多くの基礎的な データの統計量が計算されていることがわかる。ここで注意すべきは、SAS の以下のプログラム でうえのように最初に出力される標準偏差と分散は、授業で言う不偏標準偏差と不偏分散であ ることに注意せよ。
出力の最後の行は、この点を考慮してうえの結果の一部を修正した結果である。 出力は左端から順に、OBS、noss(標本数)、 xmean(平均)、xvar(分散)、u_x(不偏分散)、xstd(標準偏差)である。最初の OBS の 値 1 は、SAS 独特の出力によるもので、諸君の計算結果にはかかわりないので、無視せよ。 いずれにせよ、これらの値を、諸君の授業中に手計算した結果と比較し、手計算が間違ってい たならば、うえの結果と一致するまで各自で計算のし直しをしておくこと。そうしないと、定期 試験で合格点が取れないであろう。
![]()
上記のような少数データの出力結果を手にするためには、SAS の場合、まずデ ータに変数情報等を付けて特定のフォルダに保存しておくことはせず、それを SAS プログラムの中に入れておいて、そのまま特定のプロシジャ、例えば univairate プロシジャで分析するのが簡単である。
しかし、ここでは諸君にとって初めての SAS プログラムによる宿題なので、よ り一般的な大サンプルの場合に便利な方法として、あらかじめデータのみを data フォルダに保存しておいて、それをプログラム中から呼び出して特定のプロシジ ャで分析するやり方を勉強することにする。以下には、そのための SAS プログラ ムを示した。
このやり方の場合も、実はいろいろなやり方で最終的な結果を得ることが可能で ある。1つは、data フォルダに保存されたデータを呼び出して、データのそれぞれ に変数情報等をつけて、一旦 SAS に特有の「永久 SAS ファイル」というファイルに それらの情報を保存した上で、改めて別のプログラムにより必要なデータの分析を 行なう方法である。他方は、これらの2ステップを1つのプログラム上で行なって しまう方法である。この場合は、変数情報を付与されたデータは、SAS では「一時 SAS ファイル」という名前の一時的なファイルに保存されるが、この種のファイル はセッションが終了すると消えてしまうファイルである。
ここでは、データの変数情報の付与の後、同一プログラム内でこれらの統計量 を計算するプログラムにした。プログラム名は、basic_stat.sas とする。 以下に、ecip に (1) 平成28年度から導入された SAS 無償バー ジョン用のプログラムと (2) 平成27年度まで導入されていた SAS バージョン 9.4 等でのプログラムを順に示す。平成28年度からは、(1)の無償バージョン の方しか使えないので注意せよ:
*-------------------------------------------------------------------------* | February 2, 2016 | | file name: basic_stat.sas | | | | a sasprogram for computing some basic statistics on a set of data. | | | *-------------------------------------------------------------------------*; filename data "/folders/myfolders/data/basic_stat.txt"; options ps=60; data work1; infile data; input ssno 2. x 3.; label ssno='subject number' x='mark of a test'; run; title 'Some statistics on a set of data'; proc univariate data=work1; var x; output out=work2 n=noss mean=xmean var=u_x; run; title 'compute the unbiased estimate of variance'; data work3; set work2; xvar=u_x*(noss-1)/noss; xstd=sqrt(xvar); run; title 'print the mean, var, u_x, and std'; proc print data=work3; var noss xmean xvar u_x xstd; run; |
![]()
*-------------------------------------------------------------------------* | April 1, 2005 | | file name: basic_stat.sas | | | | a sasprogram for computing some basic statistics on a set of data. | | | *-------------------------------------------------------------------------*; filename data "p:\data\basic_stat.txt"; options ps=60; data work1; infile data; input ssno 2. x 3.; label ssno='subject number' x='mark of a test'; run; title 'Some statistics on a set of data'; proc univariate data=work1; var x; output out=work2 n=noss mean=xmean var=u_x; run; title 'compute the variance & standard deviation'; data work3; set work2; xvar=u_x*(noss-1)/noss; xstd=sqrt(xvar); run; title 'print the mean, var, u_x, and std'; proc print data=work3; var noss xmean xvar u_x xstd; run; |
![]()
保存するためには、ダウンロードコーナーの basic_stat.sas を、マウス を右クリックして現れる選択肢から必要なアイテムを選択する必要がある。ここで、 必要なアイテムは、IEと Chromeでつぎのように異なるので注意せよ:
なお、この時、画面上左上の「保存する場所」の指定を間違えないようにすること。
一方、ファイル名は諸君が入力せずとも自動的にファイル名欄に入っているはずである。また、 「名前をつけて保存」ウインドウの下方の「ファイルの種類」欄には、自動的に「sas ファイル」 が選ばれているので、改めて入力する必要はない。
なお、「名前をつけて保存」ウインドウで、「開く」をクリックしてしまうと、SAS が起動し てしまうので、「開く」をクリックしないこと。
| basic_stat.sas |
![]()
脚注1 : 通し番号は新1年生は学籍番号の 下3桁、それ以外の学生は第1回目の授業の時決められものを用いること
脚注2 : 小数点は、同一列内の数字 3 と 8 をダブルマークせよ